
The Missing Layer: Why Data Quality and Decision Traces Aren't Enough
What 12 months of building AI systems for wealth management taught us about what actually matters
Two frameworks are dominating the AI infrastructure conversation right now.
The first is Farbod Nowzad’s “Hierarchy of Data.” His argument: model quality is no longer the constraint. Data is. He’s built a four-layer pyramid (basic identifiers → complete information → derived insights → action drivers) and argues we’ve crossed the “Finally Good” threshold where enrichment actually works at scale.
The second is Foundation Capital’s “Context Graph” thesis. Their argument: the trillion-dollar opportunity isn’t better data. It’s capturing decision traces. The reasoning that connects data to action. The whispered approvals. The “we tried this before and it blew up” institutional knowledge that lives in Teams and Zoom calls.
Both frameworks are compelling. Both are right. And both are missing something fundamental.
At Humanity Labs we’ve spent the past 12 months building AI systems that execute real business processes for wealth management firms. Not chatbots. Not copilots. Systems that do actual work: opening accounts, processing transfers, generating compliance documentation, handling client service requests.
What I’ve learned is that clean data and decision traces are necessary but not sufficient. There’s a third layer that nobody is talking about. And it’s the only one that compounds.
What the data camp gets right
Farbod’s hierarchy resonates because we lived it.
Early on, we assumed the hard part would be the AI. Get a good model, connect it to the right APIs, and execution would follow. We were wrong.
The first workflows we tried to automate failed for boring reasons. Client names were inconsistent across systems. Account numbers had different formats in different databases. The same person appeared as three different records. The model was fine. The data was broken.
This matches Farbod’s Layer 1 problem exactly: basic identifiers and data quality. Without it, nothing else works. You cannot reason on top of broken records.
We spent months building reconciliation logic, normalization rules, and identity resolution. Not glamorous work. Essential work.
So yes. Data quality is the foundation. Farbod is right that we’ve crossed a threshold where enrichment can work at scale. And he’s right that most enterprises are still stuck at Layer 1.
What the context graph camp gets right
Foundation Capital’s thesis also resonates because we lived it too.
Once data was clean, we hit a different wall. The system had the right information but made the wrong decisions. Not because the model was bad. Because it didn’t know the context.
A simple example: a client requests a fund transfer. The data says the account is open, the balance is sufficient, the request is valid. But there’s a note from six months ago that this client’s son has trading authority only on Tuesdays and Thursdays due to a family arrangement documented in a memo that lives in a shared drive somewhere.
The decision trace exists. It’s in email. It’s in a case management note. It’s probably in a Teams thread. But it’s not connected to the record in a way an AI system can query.
Foundation Capital calls this the “context graph.” The reasoning behind decisions. The precedents. The exceptions. They argue this is where the real value lives.
They’re right. A system that knows WHAT without knowing WHY makes confident mistakes.
What both camps miss
Here’s where my experience diverges from both frameworks.
Clean data tells you WHO and WHAT. Decision traces tell you WHAT HAPPENED and WHY.
Neither tells you HOW TO DO THE WORK.
This is the operational layer. It’s not data about customers. It’s not records of past decisions. It’s the actual mechanics of execution. The workflows. The sequences. The edge cases. The firm-specific logic that determines whether a process succeeds or fails.
Let me make this concrete.
Two wealth management firms can have identical data quality. Both can have perfect context graphs capturing every decision ever made. But one firm processes account transfers in 3 steps and the other requires 7. One firm has a compliance officer who needs to approve anything over $100K. The other has a $500K threshold but requires two approvers. One firm uses DocuSign. The other uses a wet signature process that involves FedEx.
None of this is “data” in Farbod’s sense. None of it is “decision context” in Foundation Capital’s sense. It’s operational knowledge. And it lives in people’s heads.
When you hire a new employee, they spend months learning this. Not learning the CRM. Not learning what decisions were made. Learning how work actually gets done at this specific firm.
That’s the layer both frameworks miss.
Organizational memory: the third layer
I’ve started calling this “organizational memory.” Not because it’s a perfect term. But because it captures something important: this knowledge accumulates over time.
An employee on day one knows the systems. An employee on year three knows the shortcuts. Knows which exceptions are real and which are hypothetical. Knows that the compliance officer is flexible on deadline extensions if you ask by Thursday but inflexible on Fridays. Knows that the client service team prefers phone over email for urgent requests. Knows that one custodian’s API fails silently and requires a manual check.
This is operational knowledge. It compounds. And it’s what separates AI systems that demo well from AI systems that actually work.
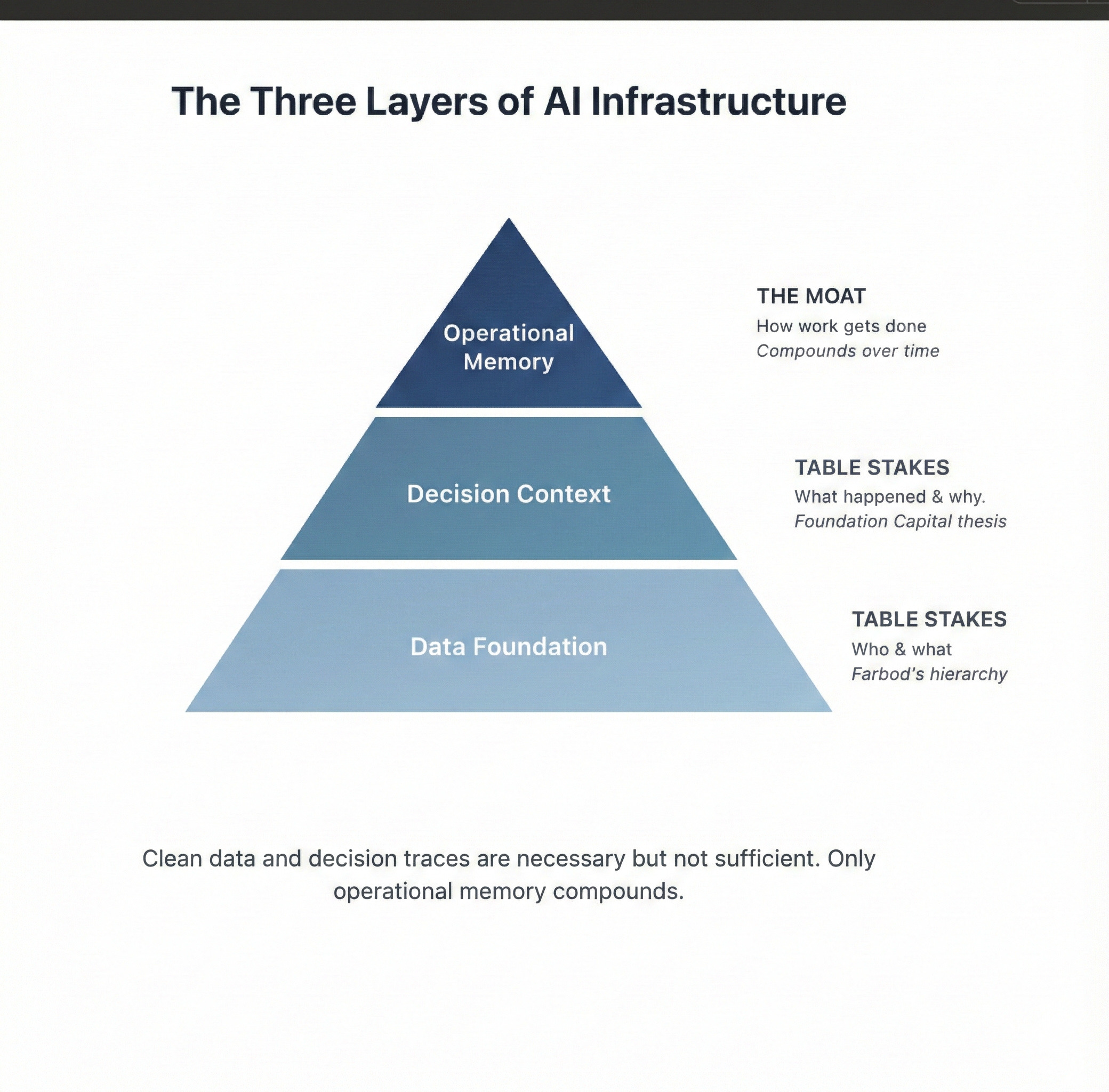
Here’s the framework I now use:
Layer 1: Data foundation Clean identifiers, accurate attributes, normalized records. Necessary. Not differentiating. This is what Farbod describes. It’s table stakes.
Layer 2: Decision context Historical traces, precedents, reasoning, exceptions. Necessary. Not differentiating. This is what Foundation Capital describes. It’s also table stakes.
Layer 3: Operational memory How work gets done. Workflows, sequences, firm-specific logic, accumulated exceptions. This is the moat.
Why operational memory compounds
Data enrichment is a commodity. Cashmere, Clearbit, ZoomInfo, Apollo. They’re all converging on the same data. You can buy it.
Context graphs can be built by anyone with access to your systems. Plug into Teams, email, calendars, CRM. Record everything. The infrastructure exists.
Operational memory is different. It’s proprietary by definition. It can only be built by doing the work. And every workflow executed makes the next one better.
When our system processes a thousand account openings for a specific firm, it learns things that no external data source knows. Which fields actually matter vs. which are optional. Which validation errors are real vs. which can be overridden. Which downstream systems need notification vs. which update automatically.
This knowledge doesn’t exist in a database. It doesn’t exist in decision traces. It exists only through execution.
That’s why it compounds. And that’s why it’s the moat.
The metric that matters
If you’re evaluating AI systems for enterprise operations, the wrong question is: how clean is the data?
The slightly better question is: does the system capture decision context?
The right question is: does execution reliability improve over time?
Not perfect execution on day one. That’s unrealistic. But measurable improvement. The system should get better at the same workflows. It should handle more edge cases. It should require less human intervention.
We track this obsessively. The metric we use is “FTE Capacity”: how much human work does the system reliably replace? Early on, the answer was minimal. Now it’s substantial. And it grows every month because the operational memory accumulates.
This is the number I’d want to see from any AI system claiming to do real work. Not data coverage. Not feature lists. Show me the trend line on execution reliability.
The gap will widen
The AI infrastructure debate will continue. People will argue about data pyramids and context graphs and semantic layers. These are real considerations for real problems.
But the companies that win will be the ones that figure out the third layer. The operational memory that can only be built through execution.
Every enterprise will have enriched data. Every enterprise will have decision logs. The question is: which ones will have AI that actually works?
The answer is the ones that accumulate operational knowledge faster than their competitors. The ones where every workflow executed makes the system smarter. The ones that treat AI not as a feature but as a learning system.
Clean data is table stakes. Decision traces are necessary. Operational memory is the moat.
The gap will widen quietly at first. Then all at once.